People seem to throw these phrases around like without a care in the world. Sometimes they’ll come up with new catchy ones as well: just tack “continuous” onto a noun and you’ve got yourself a brand new revolutionary paradigm. Continuous testing, continuous architecture, continuous compliance and continuous what not. Stop and ask what they truly mean, though, and things easily get awkward. Let’s try to split the difference between all these continuous practices and see if we can work out how they relate to one another. But first, why does any of that matter?


Preamble: This article is adapted from Chapter 2 of Continuous Practices: A Strategic Approach to Accelerating the Software Production System, by Daniel Ståhl and Torvald Mårtensson. Compare prices and availability.
On Semantics
It is not uncommon to hear phrases such as “that’s just a matter of semantics” or similar, arguing that some distinction or other is of little importance. Indeed, some will point out that any difference between, say, continuous delivery and continuous deployment is only a matter of semantics. And they would be right: it is a matter of semantics. Where they would be wrong, though, is that it is unimportant.
What is semantics, then? Semantics is simply the meaning and interpretation of a word, a sentence, a sign or a phrase. And, arguably, the meaning of the words we use is the single most important aspect of language: without agreed upon semantics, we may just as well utter random noises for all the good it will do us. And all too often, that’s what we seem to be doing when we speak to one another about continuous practices.
Some readers may object to this gloomy picture of current state of affairs. Surely, it’s not as bad as all that? Surely, we have a fairly good understanding of what these continuous practices mean? They’re about speed in software development, for the purpose of better productivity, predictability, time to market and such. And that’s right, it is about those things, but the devil is in the details. It’s possible to imagine any number of actions one might take that would fit that description, and not all of them are necessarily very helpful. Indeed, looking at continuous integration implementations we see a great deal of divergence in interpretation and implementation1, as well as – unsurprisingly – outcomes2. For instance, we have watched projects develop a severe case of tunnel vision, spending huge resources on constructing elaborate and advanced pipelines to build and test their software in order to achieve continuous integration. At the same time they have completely ignored all the other impediments actually keeping their developers from committing frequently and consequently changing little in terms of actual behavior.
Granted, definitions of continuous practices are not always as fuzzy as the example above, but in our interactions with industry projects trying to implement them the level of understanding is surprisingly often at that rather hazy level. It is also striking how often they are described in terms of what one hopes to achieve with them (this is particularly the case when it comes to DevOps, to which we devote an entire chapter in the book). There is even a tendency to deliberately avoid concrete definitions in favor of focusing on values, thereby allowing everyone to find the solution that suits their particular context best. There is a certain rationality to this: the software engineering community is indeed highly diverse, and one size will most certainly not fit all. But it is also highly problematic, in that it leaves each one of us to find our own path to salvation.
To illustrate the point, let us assume we were introducing a new diet, which focuses on eating nutritious food in the interest of being healthy and living longer. All of which is great – who can argue with that? The problem is that followers of this diet will inevitably end up interpreting it in very different ways. Some will stay away from meat, others will go low carb, others will eat nothing but carrots. They all share the same values and they all want the same thing; unfortunately they will achieve very different results, and some will end up hospitalized or worse as a consequence.
That part about carrots is not a joke, by the way. A distant relative of mine once tried an all carrot diet, and yes, he did wind up hospitalized for severe nutritional deficiency. My takeaway from that was that aiming for the stars is commendable, but figuring out your own unique way to get there isn’t guaranteed to work, and may be downright dangerous. The road to hell is paved with good intentions, and all that.
– Daniel
This is why we need to be careful about words, and try to be as precise as we can. To exemplify, when we speak of speed in continuous integration, what do we mean by that? Time from an action to a certain outcome? Which actions, and which outcomes, exactly? Or do we actually mean frequency, rather than speed? Or both? May we end up in a situation where we have to weigh one against the other? Unless we take care to sort out the semantics, we may never find out.
To conclude, semantics matter a great deal. That’s why we’re going to spend this chapter on ironing out the semantics of continuous practices: what do they mean, what do they not mean, and how do they relate to one another? Unless one is very clear on semantics, chances are that any subsequent implementation will be equally muddled.
At a workshop with several different companies which all used continuous practices, it turned out that we had very different views of what a continuous integration and delivery pipeline was. One participant stated that the pipeline ends where the developer’s code is integrated into the mainline. Another participant then argued the opposite: where the developer’s code is integrated is where the pipeline begins. Yet another participant had never heard the term pipeline before. With the definitions we propose in this book, we hope to bring clarity in such discussions and ease communication around best practices.
– Torvald
Another consequence of being careless with semantics is that it can lead to a term being essentially synonymous with “good”, which will guarantee that any impartial conversation regarding its pros and cons or whether it even applies to a certain case will not take place. Because if continuous integration equals “good”, then if one suggests that someone might not in truth be practicing continuous integration, then they are by definition bad.
We have seen this first hand in companies we have worked with, where senior management buy into the idea of continuous integration, and all projects in the company are enjoined to adopt it as soon as possible. Unfortunately, as it turns out, without first defining what would actually be considered continuous integration, with the foreseeable result that each project ends up doing its own thing. Some very valuable tools and concepts can result from that process, but it also leads to a situation where continuous integration becomes an identity, and any constructive discussion on whether they are actually continuously integrating or not becomes an attack on that identity.
Going back to the simile of diets, it’s like watching a self-proclaimed vegan eat dairy products while refusing to listen to any argument that they are therefore by definition not a vegan. Because to them, veganism permits dairy products. In other words, reckless treatment of semantics threatens to launch us straight into the realm of truthiness and alternative facts.
Continuous Integration
Even though we in the previous section deplored the fact that continuous integration and other continuous practices are often used carelessly, it is possible to identify what we would refer to as a mainstream interpretation. In the case of continuous integration, this can be traced back to the clearly formulated definition by Martin Fowler3, which states that continuous integration is “a software development practice where members of a team integrate their work frequently, usually each person integrates at least daily – leading to multiple integrations per day”.
In this definition it is noteworthy that the word “frequently” is used, rather than e.g. “quickly” or “speedily”. In other words, it is the frequency with which developers integrate that is the crucial factor, rather than the speed of builds, duration of tests or latency of feedback. Neither are the defining factors of continuous integration things like the scope of automated tests or the means of triggering builds. That does not mean that such factors are irrelevant – on the contrary, they tend to be the difference between success and catastrophe, which is why we look closely at them in the book, but they do not define the practice.
Indeed, as many will point out, in theory it is entirely possible to perform continuous integration without any automation at all. In practice, on the other hand, it depends. In trivial scenarios of one or a handful of developers, continuous integration without support from automation is certainly possible, but anything beyond that requires particular tooling and infrastructure. Precisely which tools and what infrastructure varies depending on you and your ambitions.
Think of it as mountain climbing. The definition of having climbed a mountain has nothing to do with the gear you used to get there, but is only about whether you reached the top or not. Easier climbs can be done with your bare hands, but the more difficult ones will require a range of specialized tooling, as well as skill, perseverance and constitution. Pragmatically speaking, it’s always a good idea to use a common version control repository, it’s a good idea to automatically build and test your software, and it’s a good idea to employ specialized tools for these tasks. There are already numerous excellent sources covering these aspects, such as Duvall’s book on continuous integration3, without us belaboring the point. In Continuous Practices, we instead focus on subsequent challenges you may run into once you have those bases covered, and to the best of our ability point you in the right direction to overcome them in your particular context.
In the end, returning to Fowler’s description of the practice from 2006, we only encounter two minor issues with it. One is that we prefer naming it a developer practice, as opposed to a development practice. This is partly to distinguish it from continuous delivery – a term that hadn’t yet been popularized at the time – and partly to emphasize the fact that this, unlike continuous delivery, is entirely up to the behavior of the individual developer. If the developer does not actually integrate frequently, then there is no continuous integration. The organization as such may have the loftiest ambitions and the fanciest software pipeline, but it all comes down to how the individual developer behaves. That being said, any conventions, processes or directives the organization (or the individual developers themselves) institute as part of integration become part of the scope of continuous integration. Not all such processes may be conducive to frequent integrations, but whatever steps we need to perform for whatever reason to commit to the mainline need to be considered part of the practice in the individual case. In other words, continuously integrating in one case may in one case involve nothing more than performing a merge operation in the SCM system, whereas in another case it may also involve code review, passing a mandatory central compilation and test activity and then signing a legal contract in blood. While all those things may impede frequent integrations, and while we may discuss their value and necessity, as long as they exist and are mandatory they, too, need to be addressed in any effort to continuously integrate.
The second issue is regarding members of a team. In a small scale scenario this is unproblematic, but at larger scales, in organizations of hundreds or thousands of developers split into a multitude of teams all working on the same software, it becomes ambiguous. What does “team” refer to in that context? One out of the hundreds of actual teams in the organization? Or is the “team” all the developers working on the same source code?
One may argue that such large scale setups are a bad idea and should be avoided, making the point moot. As Beck puts it, software should be split “along its natural fracture lines”5 into smaller pieces to avoid this situation – and not just for the sake of continuous integration. This is a valid point, and in our book on continuous practices we discuss the interplay between software architecture, organization and continuous integration at some length, but reality doesn’t always look like that. In reality, the same source code is very often developed by more than a two pizza team, and in those situations it needs to be made very clear that continuous integration is not about frequently integrating only with your nearest colleagues, but with everyone who is collaborating with you on the source code. No matter how quickly developers commit to their team branch, if they only deliver from that team branch to the shared project mainline (or master branch, trunk, dev branch…) once a week, then they are not continuously integrating – at least not with everyone who coinhabits the source code, which is what really matters.
Hence, when we use the term continuous integration, we mean a developer practice where developers integrate their work frequently, usually each person integrates at least daily, leading to multiple integrations per day.
Continuous Delivery
In the previous section on continuous delivery we stressed the point that it is a developer practice, as opposed to a development practice. That is because continuous delivery is exactly that: a development practice. It doesn’t have so much to do with the behavior of the individual developer as with how the project or the organization decides to think about software changes and release candidates.
Similarly to continuous integration we identify a mainstream interpretation of the practice; an interpretation that goes back to the original description by Humble and Farley6, who state that in continuous delivery, “every change is, in effect, a release candidate”, whereas traditional approaches “identify release candidates at the end”. Furthermore, while simply looking at a change in the product will only let you guess whether it truly adds value without introducing faults, in continuous delivery it is the build, test and analysis activities that make up the software pipeline that determine whether this is the case. In this sense, continuous delivery presents a mindset shift towards a heuristic approach to software development.
Similarly to the case of continuous integration, however, when applying the practice to large-scale development projects this definition becomes somewhat problematic. Simply put, if there are hundreds or thousands of changes to the source code, then fully evaluating each of them in the continuous delivery pipeline typically isn’t feasible. In practice there tends to be high degree of batching of changes, often in multiple layers, throughout the pipeline. The first few activities, e.g. compilation and unit testing, may be done for every change. Higher level tests, meanwhile, requiring more time to complete, will pick up new changes as frequently as possible, but not frequently enough to test every individual change. Further downstream in the pipeline even longer running tests might pick one out of every few of those changes, and so forth. In this way, the release candidates that come out the far end up the pipeline are actually a sampling of the ones that entered it. Naturally, the less you need to batch, the better, not least for troubleshooting purposes. Also, there are parallelization techniques that help with this, as we cover in Part III of the Continuous Practices book. The fundamental principle still holds, however: which ones make it through is determined through a heuristic process, rather than through up-front analysis.
There are plenty of diverging interpretations, particularly in relation to continuous deployment and DevOps (which is why we have devoted an entire chapter in the book to discussing DevOps). The terms continuous delivery and continuous deployment are often used interchangeably7, sometimes continuous delivery is said to enable DevOps, sometimes DevOps is said to enable continuous delivery. Sometimes continuous delivery is said to be a subset of continuous deployment, and sometimes the other way around. Much of this can be explained by the fact that continuous delivery is, arguably, a misnomer. Despite its name, as explained by e.g. Jez Humble6 and Martin Fowler8, continuous delivery actually has very little to do with delivering to anyone, but rather ensuring that one produces a steady stream of new product versions which can potentially be deployed and/or released.
This distinction may appear subtle, particularly in certain domains. If the product in question is a Software as a Service solution deployed to a cloud environment under your own control, then actually deploying the software is a relatively small step. On the other hand, in the case of a mechatronic embedded system in a highly regulated market, where the target environment is owned and controlled by a third party and moving around at high speed on public highways, going from producing a ready-to-go software version that could be deployed at any time and actually deploying it is a significant step.
It is important to emphasize that continuous delivery entails everything up to that deployment step, however: any testing, packaging, documentation, certification or digital signing required needs to be included in the practice of continuous delivery. In this sense it is analogous to the continuous integration. Just like everything involved in integrating is by definition part of continuous integration in the individual case, everything involved in creating a ready-to-go release candidate is part of the scope of continuous delivery. This means that these practices may express themselves rather differently from case to case, something we dig further into Part II of Continuous Practices, by providing multiple archetypes representing various industry segments. Another possible explanation for the confusion regarding continuous delivery is the fact that as the popularity of continuous practices increases, new individuals are constantly entering the space: the finer points of the terminology and underlying concepts may appear less clear to new-comers than to old-timers, as hinted at by Andrew Phillips9.
To summarize, when we use the term continuous delivery, we mean a development practice where every change is treated as a potential release candidate to be frequently and rapidly evaluated through one’s continuous delivery pipeline, and that one is always able to deploy and/or release the latest working version, but may decide not to, e.g. for business reasons.
Continuous Deployment
As noted earlier, the popularization of the term continuous deployment largely coincided with that of continuous delivery. In fact, its coining by Timothy Fitz predates the publishing of Continuous Delivery by Humble and Farley by about a year.
If continuous delivery is about ensuring you always have an evaluated and ready-to-go release candidate on hand, and are thus able to deploy at any time, continuous deployment is about doing it. Ideally, “every commit should be instantly deployed to production”10. One exception worth highlighting is the situation where the release candidate produced by the pipeline is not a deployable product per se, but something like a library or other resource that may be integrated into other systems. This scenario of pipelines feeding into other pipelines is covered further detail in the book.
Implementing continuous deployment implies the same capabilities as continuous delivery, but adds a slew of additional challenges. Which challenges, precisely, depends on the business domain and risk profile of the individual case, something we investigate further in Chapter 20 of the book. On the technical side of things, such challenges revolve around traceability and the ability to upgrade software in production with zero downtime – something that ultimately boils down to fundamental architectural choices in the design of the software. On the not-so-technical side, challenges one might face involve customer relations and trust issues, as well as purely contractual and regulatory hurdles.
It is worth pointing out that there are two main incentives for adopting continuous deployment in an organization. One is improved effectiveness in software development, while the other is the ability to rapidly and frequently bring value to the customers and/or users. In other words, continuous deployment can either be driven from within the development organization, or from business needs. While one incentive doesn’t preclude the other, it’s important to be carefully and explicitly consider why one adopts continuous deployment in the individual case. Without a clear vision and purpose it’s easy be led astray. We would also caution readers that even when continuous deployment is driven from within for the sake of improving software development, it will inevitably affect the entire organization in a way that continuous integration or delivery don’t. This is why it’s critical to get not just the R&D side of the house onboard, but also e.g. sales and marketing.
Proponents of continuous deployment also tend to emphasize the importance of failing fast and valuing mean time to recovery over mean time to failure. Indeed, one might argue that the practice embodies these values: it is better to deploy quickly, get feedback, and rapidly fix any failure (or, barring that, roll back) than to spend too much time and effort trying to avoid the failure in the first place.
If continuous deployment is about more or less instantly deploying to production, one obvious but often overlooked conclusion is that this practice is not applicable to every domain, mainly for two reasons. First, not all software is pushed to consumers. While the “X as a Service” trend promises to change this, a very significant portion of software is still user installed. Second, the premise that mean time to recovery holds sway over mean time to failure doesn’t always hold true. In safety critical systems, where even a minimal downtime can literally be the difference between life and death, continuous deployment isn’t necessarily invalidated, but a large part of its incentive is inapplicable.
On a slightly more pedantic note, let us consider how continuous deployment relates to continuous delivery. There are two main interpretations here: either continuous deployment is viewed as a superset of continuous delivery (and frequently continuous integration as well), or as something that follows on top of it – an extension to continuous delivery. The former view is expressed by Timothy Fitz, stating that “continuous deployment includes [continuous delivery] practices, and then some”11.
Recalling an earlier simile, mountain climbing implies walking (and a great number of other abilities), but reading a book on mountain climbing one doesn’t expect to go into any depth on the problems and virtues of putting one foot in front of the other (as fascinating a subject at that is, as any robotics researcher will tell you). To keep the scope of each practice manageable, we take the same approach to continuous deployment and delivery, regarding continuous delivery as a prerequisite, but not a subset, of continuous deployment. As Jez Humble puts it, even though “continuous deployment implies continuous delivery the converse is not true” [17]. This distinction allows us to cleanly separate the challenges related specifically to continuous deployment from those relevant to continuous delivery. It also lets us see that continuous deployment is not so much about software development, as it is about software operations.
To conclude, when we use the term continuous deployment, we mean an operations practice where release candidates evaluated in continuous delivery are frequently and rapidly placed in a production environment, the nature of which may differ depending on technological context.
Continuous Release
This article is not about continuous release, and neither is it among the “big three” recognized continuous practices. Even so, we would spend a moment introducing it, if for no other reason than to delineate continuous deployment and clarify what it isn’t.
Putting software into production does not necessarily equate making it available to users: consider practices such as limited deployments for feature experimentation, canary deployments and dark launches. Canary deployments and dark launches are similar practices, where deployments are made only to a small user base in order to test the software and collect feedback before exposing it to a larger user base – and to contain the damage in case of failures. The difference between a canary deployment and a dark launch, as we use the terms (just as with continuous practices, there is a certain level of confusion and careless use of jargon in the industry on this point), is that in a dark launch the feature is invisible to the end user. In other words, it is typically used to roll out the infrastructure and to monitor e.g. performance impacts in preparation of launching a feature.
In all of these practices, software is deployed to production without being made generally available. Conversely, as already explored, making software generally available does not necessarily equate deploying it to production, particularly in cases where there is no actual production environment under the producer’s control.
This is where the continuous release practice comes into play. Continuous release is a business practice where release candidates evaluated in continuous delivery are frequently and rapidly made generally available to users and/or customers. From an engineering point of view there is really very little to it: assuming that continuous delivery is done right, continuous release should involve nothing more than pushing a button, if that. This is why we do not delve into any details on continuous release in the book – it is ultimately a question of business strategy and therefore outside of our scope.
Putting It All together
Describing each practice by itself is all well and good, but we haven’t so far considered the big picture – how those pieces connect to form a greater whole. If you will, we have so far identified the pieces of the jigsaw puzzle, but we haven’t actually tried to put them together. The figure below shows how these pieces together form a continuous integration, delivery and deployment pipeline.
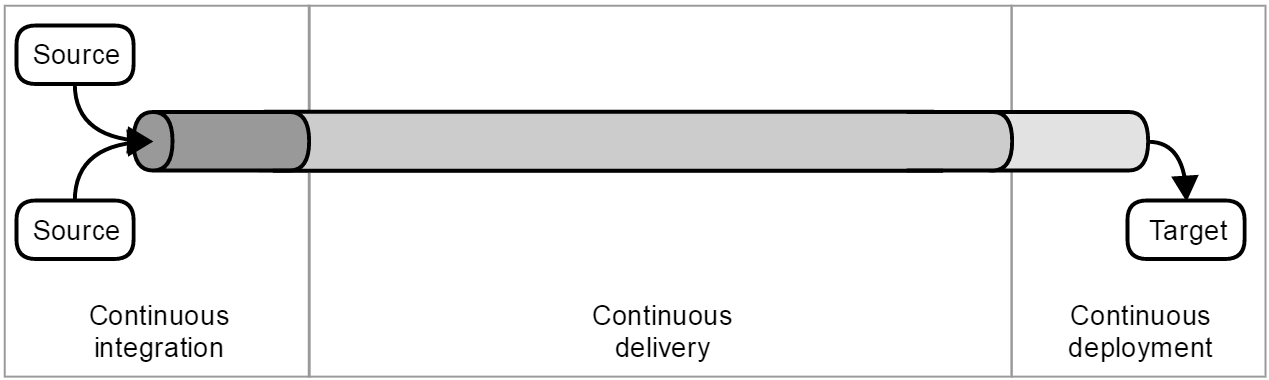
In this view, continuous delivery makes up the bulk of the pipeline itself; this is where the majority of testing, analysis, evaluation and promotion of the release candidate itself takes place. Continuous integration, on the other hand, is where those release candidates are created. In this sense it constitutes the instep of the pipeline, but continuous integration is more than that: it is the actual practice of frequently integrating the sources that go into making those release candidates, whether those sources are source code, media, third party libraries, component dependencies or documentation. Continuous deployment forms the very end of the pipeline, taking the release candidates and overseeing their deployment into the target environment.
Summary
In this article we started off by discussing semantics and why agreeing on what a word actually means is important. From there we moved on to take a closer look at continuous integration, delivery and deployment as individual practices and discussed the finer points of their definitions and how they relate to one another:
- Continuous integration is a developer practice where developers integrate their work frequently, usually each person integrates at least daily, leading to multiple integrations per day.
- Continuous delivery is a development practice where every change is treated as a potential release candidate to be frequently and rapidly evaluated through one’s continuous delivery pipeline, and that one is always able to deploy and/or release the latest working version, but may decide not to, e.g. for business reasons.
- Continuous deployment is an operations practice where release candidates evaluated in continuous delivery are frequently and rapidly placed in a production environment, the nature of which may differ depending on technological context.
1. Ståhl, D., & Bosch, J. (2014). Modeling continuous integration practice differences in industry software development. Journal of Systems and Software, 87, 48-59.↩
2. Ståhl, D., & Bosch, J. (2013). Experienced benefits of continuous integration in industry software product development: A case study. In The 12th IASTED International Conference on Software Engineering, (pp. 736-743).↩
3. Fowler, M. (2006). Continuous Integration.↩
4. Duvall, P. M. (2007). Continuous Integration. Pearson Education India.↩
5. Beck, K. (2000). Extreme programming explained: embrace change. Addison-Wesley Professional.↩
6. Humble, J., & Farley, D. (2010). Continuous delivery: reliable software releases through build, test, and deployment automation. Pearson Education.↩
7. Rodriguez, P., Haghighatkhah, A., Lwakatare, L. E., Teppola, S., Suomalainen, T., Eskeli, J., & Oivo, M. (2016). Continuous deployment of software intensive products and services: A systematic mapping study. Journal of Systems and Software.↩
8. Fowler, M. (2013). Continuous Delivery.↩
9. Phillips, A. (2016).Interview on Software Engineering Radio.↩
10. Fitz, T. (2009). Continuous Deployment.↩
11. BlazeMeter (2015). 5 Things You Should Know About Continuous Deployment… by the Man Who Coined the Term.↩
12. Humble, J. (2010). Continuous Delivery vs Continuous Deployment..↩