The core around which all continuous practices revolve is the production of release candidates. These are the release candidates built from the continuously integrated changes, the release candidates built, tested, evaluated and documented in the continuous delivery pipeline, and eventually continuously deployed into the target environment. In our experience, when asked what they find most challenging about continuous integration and delivery, most engineers tend to say something about test automation. Indeed, automating one’s testing, achieving sufficient confidence in release candidates to automatically release and/or deploy them is certainly a daunting challenge – particularly in the case of complex safety critical systems. This is something we look closely at in Continuous Practices, but constructing those release candidates in the first place is no trivial task, either. In this article we will bring up several success factors that we have identified through experience and research.


Preamble: This article is adapted from Chapter 16 of Continuous Practices: A Strategic Approach to Accelerating the Software Production System, by Daniel Ståhl and Torvald Mårtensson. Throughout the book five industry archetypes are used to exemplify common situations, behaviors and contexts. These are Jane in the defense industry, Bob who’s developing a social media platform, Mary in telecommunications, John in the gaming industry and Alice in the automotive industry. They are described in greater depth in Chapter 5 of the book.
Integration Time Modularity
Integration time modularity particularly applies to large scale software projects. As we describe in Chapter 11 of Continuous Practices, there’s a correlation between the number of people collaborating on any single piece of software and their behavior: the more people, the more infrequently the individual developer tends to commit her changes. Intuitively and anecdotally, it is reasonable to expect the same to also apply to the size of the actual software, although we don’t have quantitative data to back up such a claim (partly because consistent measurement of software size in a way that makes cross-product and cross-domain comparisons meaningful is surprisingly challenging).
In other words, unless a large software system can be broken down into smaller pieces – pieces within which engineers are able to operate more or less autonomously – integration should not be expected to be all that continuous. Apart from just making things go faster, a proven solution to the problem is a modular architecture1, and various strategies for continuous integration of software modules have been proposed in literature2,3.
It’s important to be clear on the fact that there are several types of modularity. A product can be highly modular in the sense that its functionality is realized by multiple collaborating and communicating parts of executing software, yet be built from a single monolithic code base. Conversely, a single-process monolithic runtime system may be built from any number of independent sources, all with their separate life-cycles. We refer to this as runtime modularity and integration time modularity, respectively. Purely from the perspective of producing release candidates, integration time modularity is critically important, while runtime modularity is irrelevant. From a deployment perspective, on the other hand, the opposite is true (see Chapter 20 of Continuous Practices).
Taking a holistic view they are of course both important. One way of thinking about software modularity is in terms of empowerment and autonomy. Something you create together with a small group of teammates is something you can take personal responsibility for, whereas a system where you are only one of thousands of engineers is not something you have any way of taking ownership of or responsibility for, regardless of slogans about end-to-end responsibility and holistic mindsets. And the sooner your personal work is merged with that of thousands, the sooner you are forced to relinquish ownership of it. In very simple terms, there are three typical situations, as shown below.
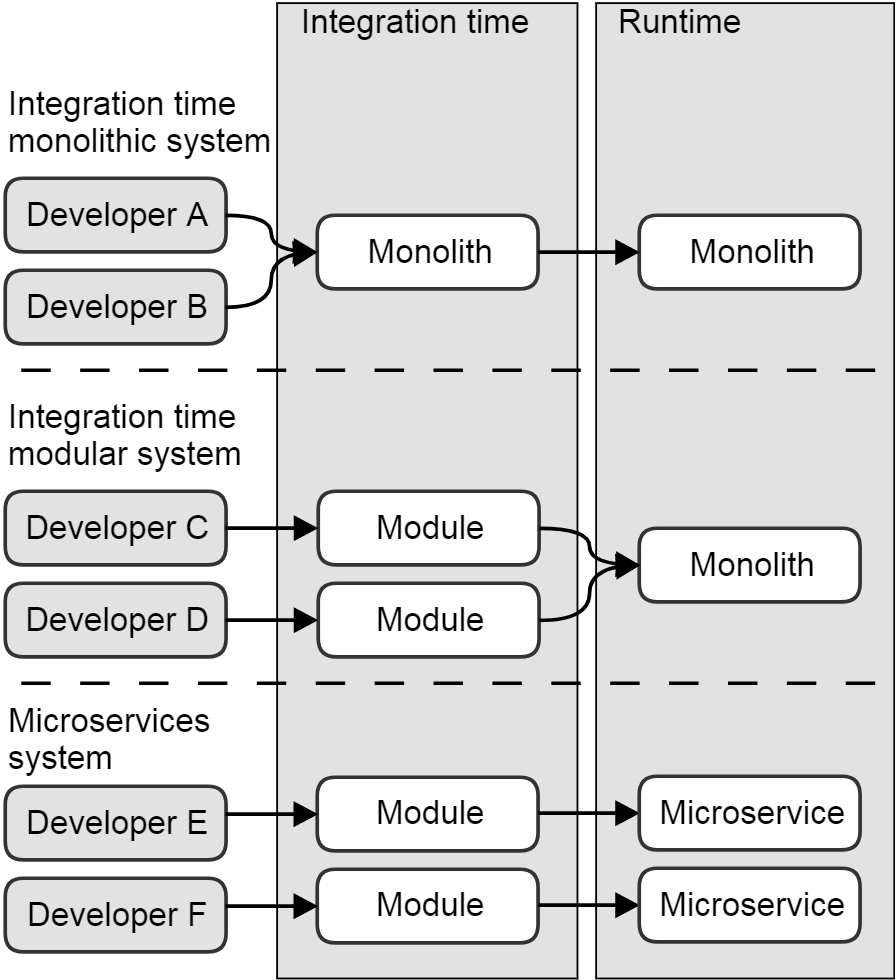
In an integration time monolith, developers A and B integrate the moment they commit sources, which means that from that point onwards in the software life-cycle they are interdependent. In an integration time modular system, on the other hand, developers C and D can build and test their respective modules independently. This means that the sources of one module can be updated without impacting parallel source changes to another module (assuming a conducive architectural split between the two). As they are integrated into a coherent, monolithic system, however, this independence and autonomy ends: neither Developer C nor Developer D can claim to “own” the larger system in runtime, and so can not take responsibility for it in its entirety.
Describing levels of modularity is incredibly difficult – there will always be corner cases and gray zones. The fact of the matter is that software designs and architectures vary so widely, that finding precise yet generally applicable concepts and language to describe them is near impossible. Daniel and I have debated these examples endlessly and tried our best to cover as many real life cases as possible, yet a perfect description of reality is always hard to achieve.
– Torvald
Finally, where modularity is preserved all the way into deployment (e.g. in a microservice style architecture), it becomes possible to take responsibility for their own service throughout its entire life-cycle, including its in-service performance and functionality. Of course, that microservice constitutes but a part of the complete solution, which neither Developers E and F still do not “own.” That being said, they can claim ownership of a clearly identifiable part of it, which is a huge step up from the other two scenarios.
A different perspective on modularity is a purely mechanistic one, and is ultimately about congestion and fragility. To illustrate the point, consider the following back-of-the-envelope calculation. Assume a large software system which takes ten minutes to fully compile, package and test any source code change to the utmost confidence (needless to say, ten minutes is rather an optimistic figure, but stay with us for the sake of argument). This means that during a typical working day of about ten hours, 60 new release candidates can be sequentially created and evaluated.
As long as the number of developers committing source code changes is low – let’s say a team of five – this is not much of an issue. If they commit once per day or several times per day, chances are the pipeline will be idle and ready to immediately act on those commits. In a worst case scenario, a change may be queued up for 10 or 15 minutes before being built and tested. Now consider the same system, but instead of five developers there are five hundred. If all of them were to continuously integrate, committing at least once per day, there would be more than 500 commits to process, but only time to build 60 release candidates. Essentially, there are two ways to handle this: optimistic parallelization and batching.
In optimistic parallelization one assumes that the latest commit was okay, even though it has not yet been tested, and so for every new commit one triggers a new build and test cycle. When a commit fails to pass, it and all subsequent commits are reverted. In batching, on the other hand, one simply runs the build and test cycle sequentially and as quickly as possible, every new run picking up the latest available commit and thereby building the entire delta that has accrued since the previous run in a single batch.
Neither of these approaches is ideal. Parallelization drives resource utilization and thereby cost, while failing to address the problem of one bad commit invalidating everything added on top of it. Batching, at the same time, suffers from fragility: the more changes that are batched, the lower the chance of the entire batch not failing the build and test activities of the pipeline. To continue the back-of-the-envelope calculation above, if one assumes that the chance of any one commit passing through the pipeline successfully is 95%, then a batch of eight commits (the average batch size in our example) would only have a 66% chance of passing through – and that is assuming zero interference between the batched commits, which is a rare occurrence.
So far we have only viewed this from the pipeline’s point of view, however. From the developer’s point of view, there is also the problem of having to stay up to date with and rebase onto more than 500 changes per day. In interviews with developers in large software development projects we find that this by itself effectively puts a soft cap on the pace of integrations. It’s not that developers wouldn’t like to continuously integrate; rather they find that when the sheer volume of incoming changes is so high, they tend to get stuck endlessly merging everybody else’s changes rather than implementing their own. Consequently they retreat into a feature branch, finish their work, and then take the pain of merging when they’re done. The ceaseless merging becomes too much like death by a thousand cuts, whereas a big bang merge at the end of development may be painful, but at least it only hurts once.
The only solution, in our experience, that adequately addresses the underlying problem is to simply avoid the situation altogether: to the extent that the software system requires such a large organization that collaborating on a single source base becomes problematic, break it apart into as autonomous a set of modules as possible, owned by teams who take full responsibility for them. In other words, a one-to-many relationship between modules and teams should be avoided, while one-to-one or many-to-one relationships are preferred.
This raises two questions, however. First, what is the right team size? How many engineers and/or developers are too many? Jeff Bezos’ two pizza rule is frequently cited: a team shouldn’t be larger than what two pizzas can feed. In our experience, this is as good a rule of thumb as any.
Second, how does one ensure the autonomy of those teams? Apart from organizational and managerial aspects of the problem, the key is to enable asynchronous evolution of software across modules. This, in turn, requires strict enforcement of interfaces with life-cycles separate from their implementations. The concept is identical to that of interface separation to enable continuous deployment in the target environment, explored in greater depth in Chapter 20 of Continuous Practices, but applied on a source code level rather than on runtime services.
Just as in the runtime deployment case, the keyword is asynchronicity. This reason is that, practically by definition, it is impossible for a development team to act autonomously if they need to coordinate their changes with a large organization in order to not break dependencies between modules. A knee-jerk reaction among many software architects is then to require developers to never break backwards compatibility in their interfaces, but this can also turn into a straitjacket, where one bends over backwards and accrues large amounts of technical debt just to stay compliant with an obsolete interface.
A more successful pattern is to allow modules to break backwards compatibility, but when doing so also maintaining their old interfaces in parallel for a limited period of time. This provides their dependents a window of opportunity where they can migrate to the new interface. This does require a certain amount of communication – the module changing its interface must broadcast that information to its dependents – but very little coordination. This is key, because nothing kills both autonomy and responsiveness as effectively as synchronization meetings and development coordination spreadsheets.
On a side note, we find that this all comes down to the question of the manufacturability – or perhaps the developability – of the software. In most engineering disciplines, manufacturability is an important concern: how can the product be designed to facilitate manufacturing and to reduce costs? In software engineering, however, this question is rarely raised. An obvious reason for this is that software is immaterial and therefore doesn’t require manufacturing the way a physical product does, but we argue that the concept as such – with a slightly adjusted meaning – is valid, and deserves more attention. In software engineering the question is not how to reduce manufacturing costs, but how to design a software product so as to facilitate its development, integration and testing. In that sense, we find that integration time modularity is a critical success factor.
Integration time modularity and, in a more general sense, manufacturability is a non-issue for some of our archetypes, either because their products are not large enough for it to be relevant, or because they are highly runtime modular. John exemplifies the former situation – the code base of his game is’t larger than he can make sweeping and consistent changes to the entirety of the game in single, atomic commits – while Alice’s car is an example of the latter, but with an important caveat. The electronic control units of her vehicle system could have been the embodiment of runtime modularity: until they are hooked up in the target environment, they exist as perfectly isolated entities, with their own isolated pipelines. Communication between the units is controlled by a central signal database, however, forcing any interface change to be synchronized not just between the affected electronic control units, but across the entire development project.
One of the products in Mary’s network equipment portfolio, on the other hand, is built into a single monolithic entity from dozens of modules, large and small, most of which produce multiple versions per day. In other words, the pace of integration is much too high for any manual intervention. Instead, the pipeline constantly rebuilds new versions of the product, swapping out old modules for new ones as they are published.
Archiving in a Definitive Media Library
The Information Technology Infrastructure Library (ITIL) is a set of detailed practices for IT service management. ITIL has achieved a fairly poor reputation in certain parts of the industry, largely because they’re just not Agile (with upper case A), or not regarded as being sufficiently agile (with lower case a), while others will argue the opposite.
Whichever side of the argument you come down on with regards to to its compatibility with agile practices, ITIL’s goal is commendable. It merely strives to standardize good practices and procedures, providing a baseline of professionalism that allows organizations to measure their performance and demonstrate compliance with regulatory standards. Whatever one’s opinions on ITIL as a whole, much of it is based on what we would label as common sense – as elusive as that may be.
One item of common sense, in particular, is the concept of a Definitive Media Library (DML). According to ITIL, a Definitive Media Library is a repository of the organization’s definitive, authorized versions of software media. In a nutshell, this means that ITIL believes you shouldn’t scatter your software artifacts all over the place, but maintain a protected storage where you can find any artifact you’re looking for.
All of which is perfectly reasonable; it is merely an example of the concept of a single source of truth. To exemplify, when the QA people in John’s company pick up a new version of the game to test, they don’t go looking for a suitable version on John’s laptop, the continuous integration server or some random Network Attached Storage (NAS) folder. Instead, they pick up the latest version published to the blessed artifact repository – their Definitive Media Library – the same repository from which releases are shipped.
Many organizations apply this principle without thinking of it in terms of a Definitive Media Library or even having heard of ITIL, and several excellent software repository tools can serve as excellent DMLs (e.g. Artifactory). That being said, using a Definitive Media Library is not just a question of tooling, but of practice.
Using a single repository as the point of access to and archiving of software (preferably in its ultimate deployment format, see Chapter 18 of Continuous Practices) leads to several benefits. First, it provides a guarantee that if software exists, it is accessible to those who should have access to it, and not to those who shouldn’t. This is also a prerequisite for sharing and reuse of common assets within the organization: if you know where to look, it’s much easier to find what you’re looking for.
One large organization I worked with struggled with the fact that the wheel would get reinvented over and over again. Instead of being developed once or twice and then reused, generic functionality like protocol serialization and deserialization would get implemented ten or twenty times in as many products. One major reason for this waste was the lack of a Definitive Media Library – there was simply no straightforward way of first finding relevant software and then managing your dependency to it. It is ironic that in many companies, it is much easier to find an external open source library that does the job than something developed internally.
– Daniel
Another benefit of having a Definitive Media Library is that it allows safe management of dependencies to third party software. If your organization is anything like most we have worked with, chances are your developers tend to pull in the dependencies they need from the Internet without much consideration of licenses, copyright permissions and trade law. And while that may be fine in an experimentation and prototyping phase, when it comes to in-production commercial software – particularly software exported across national borders – uncontrolled import of third party software can expose you to some very unpleasant and expensive surprises of the kind lawyers make their living from.
A reasonable compromise between legal compliance and developer creativity is to allow freedom with responsibility in developer workspaces, but to lock down the continuous integration and delivery pipeline to prevent it from pulling in dependencies from anywhere but the Definitive Media Library and to ensure that anything that gets stored in the DML is okay to use. That way any release candidate is guaranteed to include only approved software, internally or externally developed.
As an example of this practice, during development of one of her system’s graphical user interfaces, Mary finds an open source Javascript graph rendering library that fits her needs perfectly. She plays around with it and decides it’s the right tool for the job, and so she uploads it to her company’s third party software library. The upload fails, however: the automated static code analysis finds several files licensed under the GNU General Public License (GPL), which company policy prohibits from inclusion in commercially distributed software. In other words, since Mary’s continuous integration and delivery pipeline can only fetch software from the Definitive Media Library, this highly useful but problematic software will never make it into any release candidate. Bad news for Mary, but on the other hand, without this check her failure to manually inspect the applicable licenses would have exposed her company’s intellectual property (personally held beliefs regarding the moral and philosophical aspects of software copyright and licensing aside).
Bob also makes heavy use of a Definitive Media Library, around which the network of pipelines producing their social media software revolves. The figure below shows the pipeline producing one of the microservices making up their backend, along with a pipeline producing one of its library dependencies. As the figure illustrates, the release candidates of the library and the microservice, respectively, are produced and archived early on in the pipeline. They are then reused for multiple purposes (evaluation in the continuous delivery pipeline and downstream integration, respectively). Dotted edges represent transport of the library dependency, and solid edges represent transport of the resulting microservice.
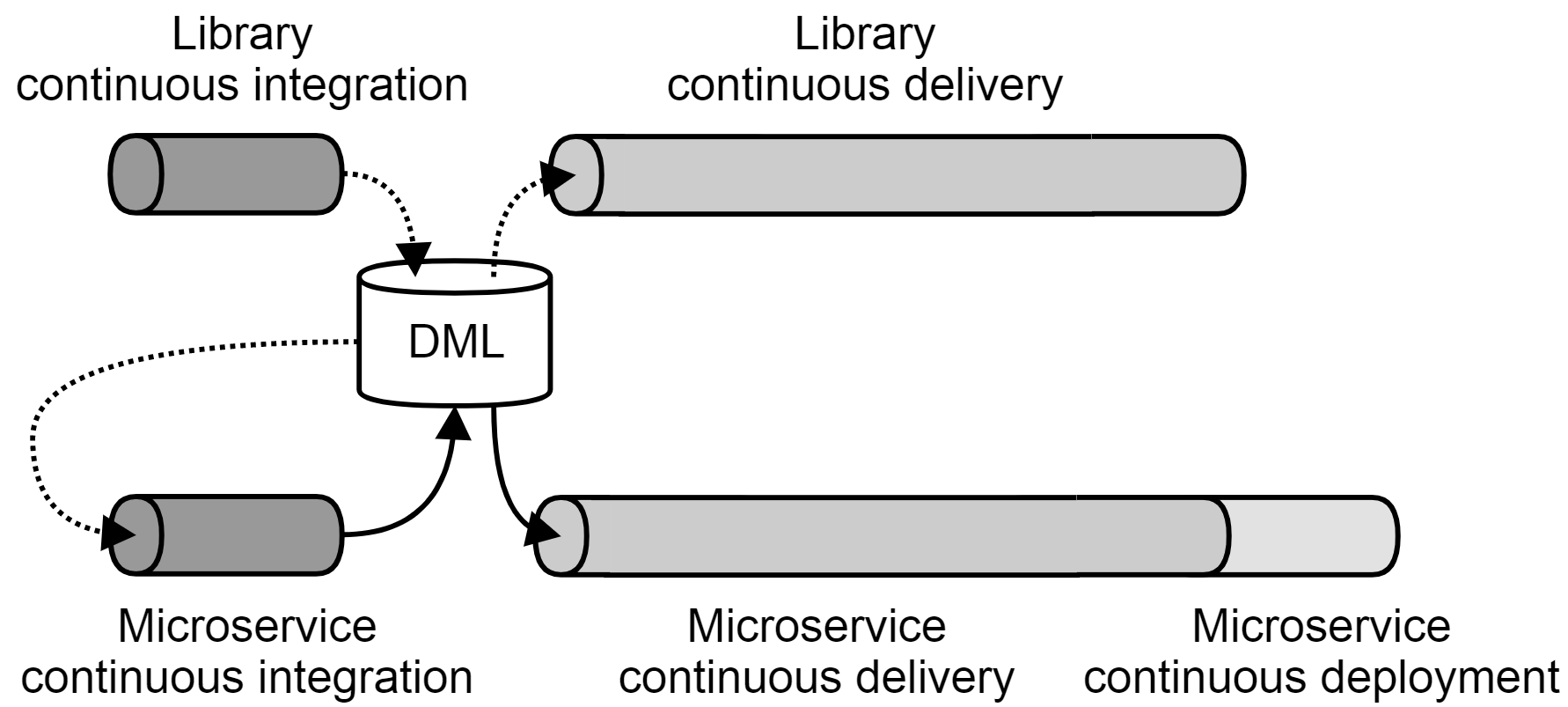
To make sense of this figure it’s important to understand that consuming relationships in a network of pipelines are not necessarily causal or temporal relationships4. We return to this issue and methods of reasoning around these distinct types of relationships in Chapter 21 of the book. For now, suffice to say that even though both the library continuous delivery pipeline and the microservice continuous integration pipelines consume the same input from the same source, that does not imply that they respond to the same triggers or execute in parallel. On the contrary, as exemplified in Bob’s case, a library release candidate is produced in the continuous integration pipeline, stored in the DML, evaluated through continuous delivery and – assuming success – stamped as being good enough for downstream integration. This causes the microservice continuous integration pipeline to pick up the exact same artifact and build it into a new version of the microservice, which is also stored in the DML, from where it is fetched by the microservice continuous delivery and deployment pipeline.
Meta-Data as Source
Transforming sources into release candidates requires all sorts of meta-data, apart from the sources themselves: meta-data such as dependencies, build tools to use, deployment instructions, runtime configurations, various types of documentation and pipeline promotion policies, as well as test case sources. A common, but unfortunate, practice is to spread this data wide across any number of auxiliary tools and databases.
I have worked on several products where I have grappled with the fact that even though the source code was conscientiously maintained in SCM systems, everything else needed to actually make use of it was scattered to the four winds. The ad-hoc build system was maintained separately and regarded as a product in its own right, the dependency information was stored in a dedicated property database, documentation was stored in multiple repositories without any direct connection to particular source code versions, and automated tests depended on scripts strewn across a number of NAS disks. Unsurprisingly, the average developer had no idea how to actually build their own software, and while reproducibility was ostensibly a strict requirement, is was something everyone quietly prayed would never actually be necessary.
– Daniel
Needless to say, we regard this as extremely bad practice. This is not least because of the damage it does to reproducibility. If, for instance, the software is built according to scripts and recipes stored in the pipeline’s build activity configuration rather than as part of the source, this means there are no guarantees that the current version of those scripts are actually compatible with any given version of the sources: if you need to go back two years in time to rebuild a particular version, you would also need to find the exact pipeline activity configuration that built it. While not impossible, this is rarely out-of-the-box functionality. Similarly, where a particular build activity depends on multiple source repositories and/or built artifacts (e.g. integrating multiple modules), how they all hang together should never be part of the build activity configuration.
Even though we in Chapter 15 of the book explain the importance of traceability, traceability alone will not help you. To understand why, think of your software product as an intricate Lego set. Having designed a stunningly beautiful Lego set, you make careful drawings of every single brick you used and how you fit them together, and then store the pieces in labeled boxes so you won’t lose them. As your design evolves you produce multiple sets of drawings and update the contents of the boxes as you go along. A few years down the line you decide to rebuild your grand creation, and thanks to your disciplined labeling and storage system you can easily gather all the individual pieces you used. To your dismay, you realize that you didn’t actually put the instructions in the boxes with the pieces, but in a binder in your bookshelf. Since then you have moved house twice, and those instructions can now be just about anywhere, and even if you find them, only trial and error will tell you which version of the drawings goes with the contents of the boxes.
Unfortunately, we come across such practices time and time again: intricate build and deployment scripts are implemented e.g. as part of Jenkins job configurations rather than as sources in their own right, and immediately all version control and configuration management considerations go out the window. To counter-act this, we offer two simple rules of thumb: pipeline activity configurations should be made as stupid as possible, preferably invoking a single shell command, and they should always map to one and only source repository, containing the necessary information to build, package, document and configure whatever the output of that pipeline is.
To exemplify this, let us take a look at the pipeline producing one of the microservices in Bob’s social media backend. It pulls in three separate libraries to build them into the deployable service. It would be perfectly possible to do this by having the pipeline activity trigger on any update in any one of these dependencies, thereby always including the latest available set of libraries, but Bob and his team have chosen to introduce a separate repository specifically to identify these libraries, thereby isolating any knowledge of their existence from the pipeline itself.
The rationale for this setup comes from the same architectural principles Bob applies to the commercial software he develops. A vital aspect of software architecture is managing the state of a system: maintaining state in as few places as possible, and only in the right places. This is because stateless software is simply much easier to deal with, in so many ways. A stateless service, for instance, is easily scalable, easily disposable and easily restarted in case of trouble. Once state is introduced, however, things get trickier. The same applies to pipelines – remember, we insist on regarding a continuous integration and delivery pipeline as any other software system – and the same architectural principles apply. Consequently, the ideal pipeline is completely stateless and only acts on the input it is given, and the best place to store that input is in a single source code repository where it is properly version controlled as atomic, coherent commits. In other words, the pipeline should be clever, flexible and powerful, yes, but it should know nothing.
This is why Bob’s team follows a strict rule of one-to-one mapping between pipelines and source repositories: every pipeline stems from one and only one repository, and all the configuration determining its behavior is found in that repository. This allows the pipeline configuration to be extremely simple – it spawns an environment (e.g. from a container image), checks out the sources and invokes a command. Any additional magic on top of that is strictly forbidden.
This makes reproducibility very simple: every built version of the software points back to one and only one revision of a single source code repository, which contains an unambiguous declaration of all dependencies included as well as the environment in which it should be built, clearly identifying e.g. compilers and environment variables. In many cases, the repositories Bob and his colleagues use to configure their pipelines contain no actual code apart from build scripts, configuration and dependency declarations: they only serve to stitch the system together.
A common misconception is that this practice implies manual updates of these repositories for every new version to be built. To trigger a build of Bob’s microservice, wouldn’t someone need to update that repository every time a new version of one of the library dependencies is published? The answer is yes, but there is no reason for that someone to be a human being. Rather, it’s a matter of separation of concerns between two automated processes. As shown in the figure below, when a new version of any of the libraries is published by their respective pipelines, a dedicated job updates the source code repository at the head of the microservice pipeline with the new dependency information. This in turn triggers a new build of the microservice, even though that pipeline knows nothing about the reasons for that change.
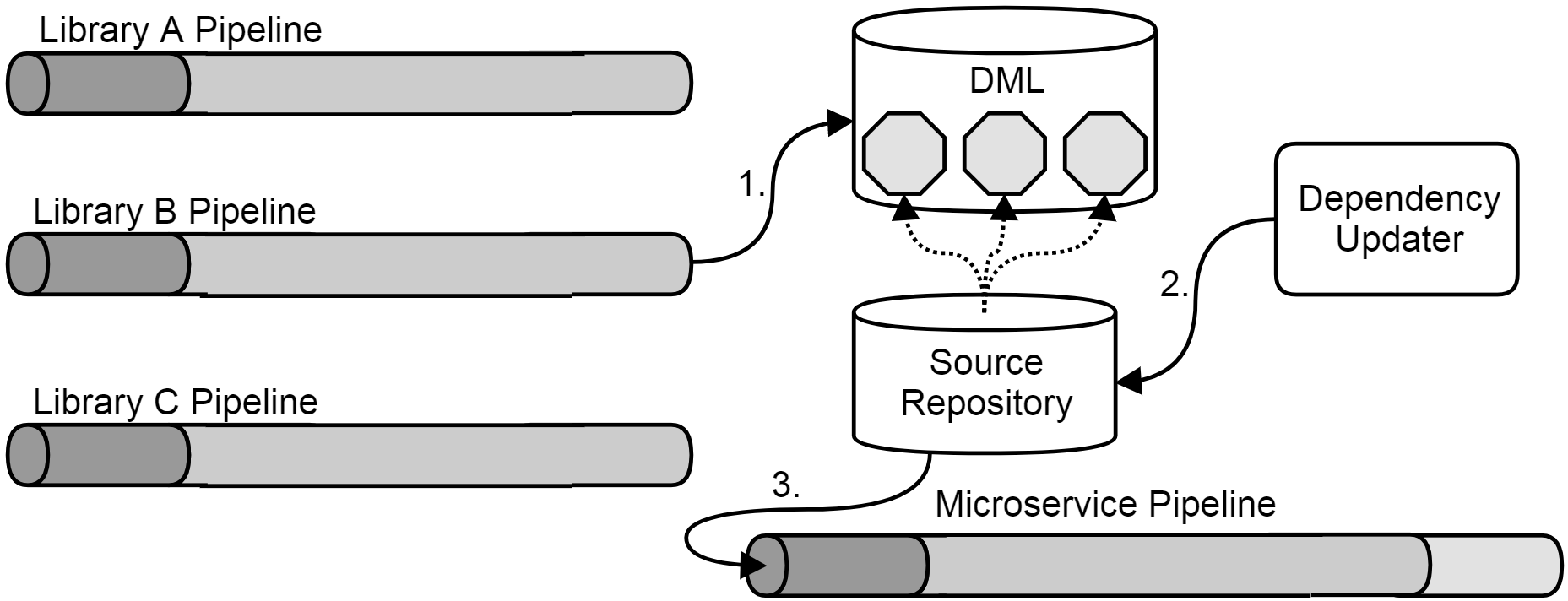
In this figure, the first step is the Library B Pipeline publishing a new version to the Definitive Media Library (DML). Second, the Dependency Updater triggers on this and commits a new version to the Source Repository, identifying the new version of Library B (represented by dotted edges). Third, this commit triggers the execution of the Microservice Pipeline, including the updated library version.
The same principle applies to configuration data, environment specifications, deployment topologies and so on. One exception, however, is the version of what is built from the sources – in other words, the version of what comes out of the Microservice Pipeline in the figure above should not be defined in Source Repository. We are well aware that in some circles this is a controversial statement, so let us elaborate the point.
First of all, we must keep in mind that the version of the source code and its derivative – that which is built from the source – are two different things. The former is best identified via the SCM system itself, i.e. via a Git hash or tag, a Subversion revision or similar. The derivative needs a separate versioning scheme, however, ideally on a format that carries some information regarding type of change and backwards compatibility (e.g. Semantic Versioning). Common practice is to store this information in the source code and step the version every time a new release candidate is created. Indeed, this is prescribed by various popular build tools.
This practice works well in cases where there aren’t too many developers involved, not too many incoming changes, and the generation of new release candidates from those changes is predictable. Essentially, when it’s just you making changes it’s easy enough to update the version according to the changes you make. If others are making unrelated parallel changes with which you need to merge, however, deciding which version to put in the source isn’t trivial, particularly when you don’t know which source revision is actually going to end up being built into a release candidate in the end (e.g. due to batching of multiple changes, as described previously in this chapter).
Some try to work around this problem by introducing fluid versions which may be published multiple times, representing work in progress, and then – when a source revision has tested to a certain level of confidence – branch it off, change the version number to a fixed one and then rebuild the release candidate from that and re-test it. We regard such practices as unnecessary complications made superfluous by changing approach to the underlying problem. Just as the source code is best versioned by the SCM system, its derivative is best versioned by the DML, rather than by the source. Every time the pipeline builds a new release candidate it can itself derive its correct version and upload it as such to the DML. The key to doing that is using commit messages to declare the type of change made.
Writing clear, informative commit messages is a highly respected skill in the software engineering community, and its importance widely acknowledged. Commit messages are not just for human readers, however. They can also inform automated agents, such as pipeline build activities, as to how to treat the commit. When developers, as part of their commit messages, declare whether the change they made is a patch, a minor change or a major change (assuming Semantic Versioning), that is all the information the pipeline needs to determine the correct version of the new release candidate.
Let us consider the software in Alice’s electronic control unit as an example. The latest software version was built into version 1.5.3. Based on that commit, Alice makes a commit tagged as representing a minor change (i.e. backwards compatible functional change) while her teammate makes a commit tagged as being a patch (i.e. a backwards compatible bug fix). The pipeline picks up the latest commit and determines that the delta since the latest release candidate is one minor change and one patch, and consequently the new release candidate version is 1.6.0. This type of analysis of commits in the pipeline has other uses as well, such as analysis of commit author and/or code changes in order to dynamically determine which tests to execute, something we return to in greater depth in Chapter 17 of Continuous Practices.
Before moving on to the next topic, we would like to issue one more word of advice on this topic. Semantic Versioning and similar versioning schemes do two things at once: they identify a linear sequence of incrementally increasing software versions, and they carry semantic information as to the relationships between those versions. This works well enough as long as that linearity holds true, but when it no longer doesn’t, the system breaks down. The ensuing problem of how to version variants and maintenance branches and how to represent their internal compatibility relationships can be a deep, dark rabbit hole that is best stayed away from. One could argue that one ought to maintain but a single development track and thus avoid the problem altogether, but as we have noted before, quoting scripture to the suffering is rarely helpful. In our experience, few developers maintain multiple branches and variants because they enjoy it – rather they are forced into it by prevailing circumstances (as we will return to in Managing Variability further on in this article). In this situation there are essentially two options. Either one gives up the semantics (or at least changes the semantics to something other than representing compatibility relationships) or one gives up on linearity. One source of inspiration here is how some SCM systems (e.g. Git) deal with the problem by representing version history not as linear sequences, but as directed acyclic graphs (DAGs).
Job as a Service
The age old developer excuse “But it works on my laptop!” in the face of in-service software failure is often derided as shirking from responsibility – after all, the developer’s job is to produce software that works in the production environment. Before we can expect that level of responsibility from developers, however, we have to give them the tools they need to shoulder it. Transparency and traceability, as discussed in Chapter 15 of the book, is one prerequisite. Another is the ability to (quickly and painlessly) test software changes in the target environment. If all the developer has access to is their laptop, then that is all they can be expected to take responsibility for.
This problem very much applies to continuous integration and delivery pipelines as well. Particularly large systems in close proximity to hardware (see Chapters 11 and 10 of the book) tend to include non-trivial test environment setups in their pipelines. These environments are used to test complex scenarios which can not be tested on a developer’s laptop.
One example of this is Alice’s continuous integration and delivery pipeline. As software is promoted through the pipeline, it is tested in various constellations of partial vehicle systems (including components such as windshield wipers, lights, brakes, steering, powertrain et cetera) and ultimately in more or less complete vehicles. Until recently, the prescribed process was for Alice to book these environments for a period of time and configure them for her tests. This is highly valuable, and she still does this on occasion, but it doesn’t tell her whether her changes will actually work in the pipeline or not. Also, the process of booking, settings up and tearing down such environments introduces a great deal of overhead leading to low effective utilization of these scarce and valuable resources.
Today, all the pipeline activities are split into two parts: triggers and jobs, with the latter being exposed as services behind network APIs. The pipeline itself is just another (privileged) user of those job services, which means that Alice can execute the exact same tests that are executed in the pipeline, but as part of her software design and experimentation process, without committing to the product mainline.
The same applies to build jobs. Rather than producing a “black” build of the software locally and trying that out, she can get her change built by the actual pipeline job, in the same environment, exactly as it would have been had she committed her software. In other words, she can create complete release candidates from any local branch of the code with the push of a button.
This is achieved by a separation of concerns between a pipeline activity’s trigger and its function, i.e. the actual job. The trigger is strictly a pipeline concern – it is the configuration that controls what gets executed when and why. The job, on the other hand, is available as a service which can be called by the pipeline or from the developer’s workspace.
The problem with most continuous integration servers is that they jumble up these two separate concerns: the job to execute and the conditions under which to execute it are blended into a single activity configuration. Separation of the two enables a cleaner pipeline architecture and reuse of the jobs: reuse both within the pipeline, having the same job execute under multiple conditions, but also reuse by developers and other stakeholders.
As depicted in the figure below, instead of building her software locally, Alice first calls the build service to compile her sources into a binary. The build job then stores the resulting artifact in the Definitive Media Library and finally returns a report, including a reference to the artifact, to Alice. Now ready to test her freshly built artifact, Alice invokes the test job’s API, including the reference to her artifact. The test job consequently fetches the artifact from the DML and, having completed its tests, returns the result to Alice. This allows her to get away from any concerns regarding consistency and reliability of build and test environments: without worrying about whether her development environment is correctly configured and up to date, she gets a correctly built binary served to her, identical to an actual release candidate. It is important to note that while in the figure it is Alice who invokes these build and test jobs, the pipeline itself would follow the exact same process. The point of this setup is that it enables developers to “play pipeline” and manually emulate selected parts of the software production system.
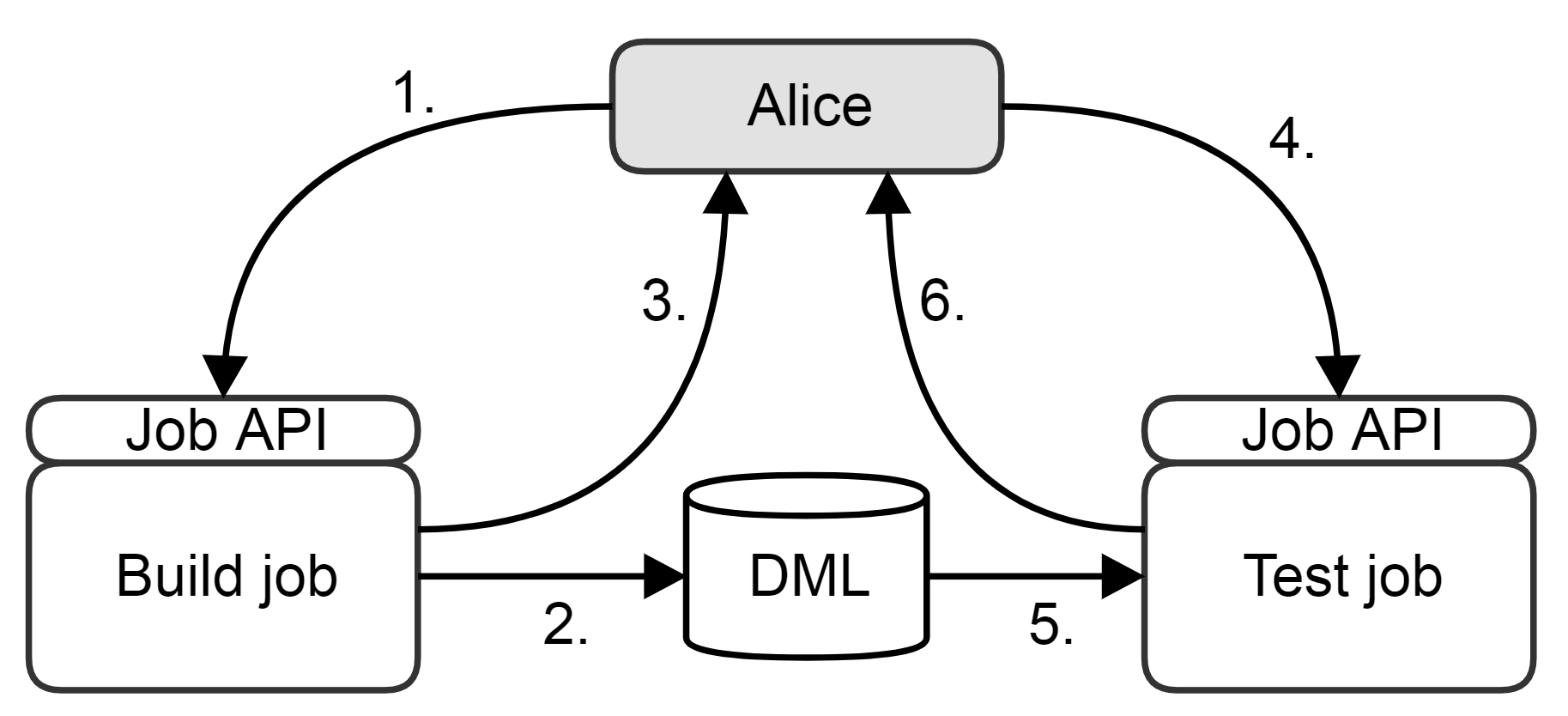
What’s more, assuming the type of self-documenting pipeline introduced in Chapter 15 of the book, Alice automatically gets full traceability of her own private release candidate in the process. In other words, to the extent her company considers that to be good practice, Alice’s private release candidate could actually be deployed to production with the same life cycle documentation as anything that passed through the canonical pipeline. Naturally, she will also want to sometimes build her own binaries, particularly when experimenting with build parameters and environment variables. The availability of the pipeline’s jobs as a service allows her to avoid lots of unnecessary errors caused by environment discrepancies.
Managing Variability
Just about every software developer would love to be able to produce a single variant of their product, which all customers would use. For some that is reality, while for others it is but a distant dream. The reasons for this go back to the power balance between producer and customer (see Chapter 8 of Continuous Practices) as well as the distribution model (see Chapter 13). It matters whether the software is a mass-market product where customers take it or leave it, or whether it is more of a partnership oriented relationship where the customer may require tailored solutions. It also matters whether the producer can deploy it to their own environment or the customers install it on their own devices where they can fiddle with it and integrate it with any number of other products.
Pious wishes aside, much of the software industry is stuck maintaining as many variants of their products as they have customers. A traditional way of dealing with this is to either create these variants at integration time (essentially maintaining one pipeline for every variant) or even worse, in development by cloning and owning the software for every customer solution. Both approaches create enormous amounts of overhead and waste – particularly the latter, as any functionality must be reimplemented multiple times, tested and verified multiple times, and even so there are no guarantees it will work the same in each variant.
Mary’s networking solution is constantly challenged by this problem. Three major customers, A, B, and C, have very different wishes and requirements on functionality. While Customer A desires Feature X, Customer B only wants Feature Y. Customer C, on the other hand, would really like both Features X and Y, but hasn’t paid for either, and Mary’s company doesn’t want to give them away for free. What Mary and her colleagues could do would be to clone the source code and develop it on separate tracks, as shown in the figure below, where individual source code revisions on each separate track is represented as a circle.
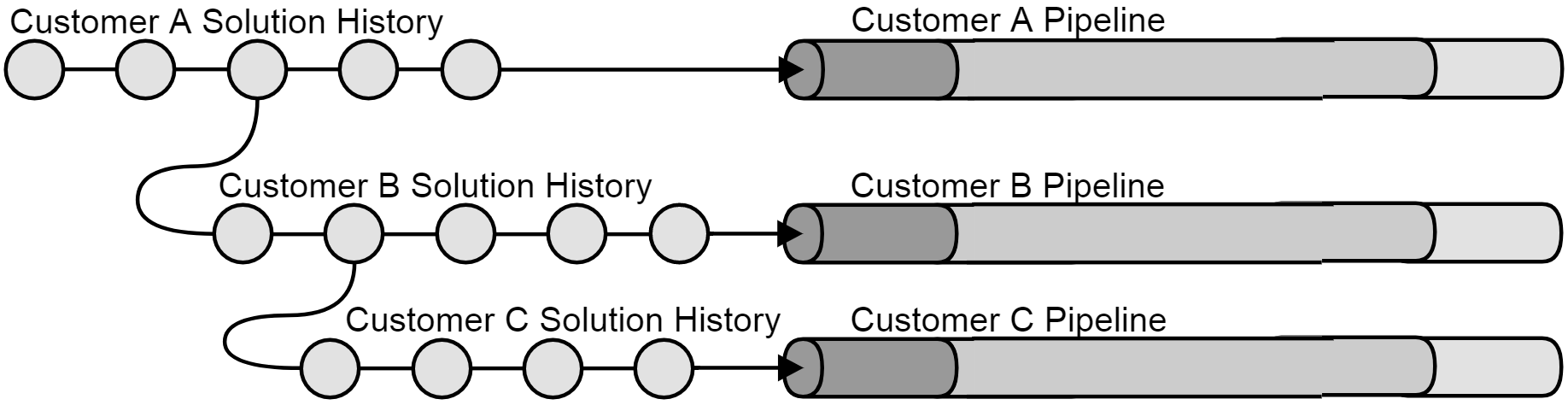
They could also split the product into parts with Features X and Y isolated in dedicated modules, which are then included or not included in the build for each customer, as shown in the next figure. Another strategy would be to supply Features X and Y as plugins to be added at deployment, and yet another to implement feature flags for activation and deactivation of particular features, e.g. based on a licensing scheme. This allows Mary to develop any given feature once and only once for all customers, whereupon who uses it and who doesn’t becomes a later concern. This practice comes with the added benefit of greater flexibility, where licenses can be enabled and disabled in runtime without even re-deploying the software. For instance, Customer C can be provided temporary trial licenses and possibly enticed into purchasing the extra features for their system.
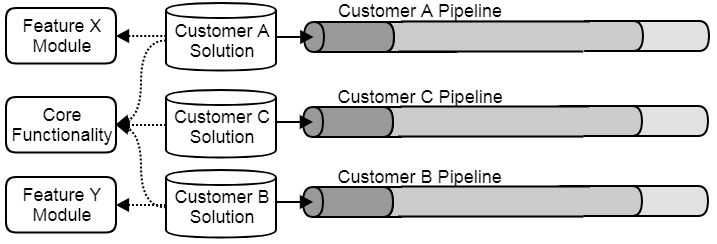
Which strategy is optimal in the given case depends on several factors. The distribution model is one, but also the proximity to hardware (see Chapter 10 of the book); for instance, in certain situations the need to minimize hardware resource utilization may override all other concerns and drive the product towards cloning just to be able to optimize each individual customer solution.
Regardless of strategy the variability problem doesn’t quite disappear, however, at least not from a verification point of view. Particularly in safety critical contexts (see Chapter 7 of the book), each unique combination of license activations may be regarded as a variant to be verified, whereupon the demands on the testing resources of the pipeline will literally increase exponentially, unless sufficient functional isolation between the variants can be demonstrated. There are strategies to get around this, which we are investigated in Chapter 19 of Continuous Practices, but it may be worthwhile for the business side of Mary’s company to perform a cost-benefit analysis of complying with these wishes before choosing either strategy. It is quite conceivable that such an analysis would reveal that sticking to a single variant containing all the features at a lower price, but also developed at a lower cost, would be more profitable – even if it meant losing Customer B, who absolutely do not want Feature X, in the process.
Summary
In this article we have identified success factors for effectively producing release candidates. Careful consideration of the architecture both of the pipeline and of the software product itself can greatly impact one’s ability to rapidly and consistently produce new release candidates. In other chapters of Continuous Practices we will look into techniques for evaluating those release candidates, packaging and documenting them, deploying them, as well as the meta-question of how to go about designing a pipeline that is fit for your particular purpose.
1. Rogers, R. O. (2004). Scaling continuous integration. In International Conference on Extreme Programming and Agile Processes in Software Engineering (pp. 68-76). Springer Berlin Heidelberg.↩
2. Roberts, M. (2004). Enterprise continuous integration using binary dependencies. In International Conference on Extreme Programming and Agile Processes in Software Engineering (pp. 194-201). Springer Berlin Heidelberg.↩
3. Van Der Storm, T. (2008). Backtracking incremental continuous integration. In 12th European Conference on Software Maintenance and Reengineering (pp. 233-242). IEEE.↩
4. Ståhl, D., & Bosch, J. (2016). Cinders: The continuous integration and delivery architecture framework. Information and Software Technology.↩